2. Придумываем бэкпроп#
У Маши есть нейросеть с картинки ниже, где \(w_k\) — вес для \(k\)-го слоя, \(f(t)\) — какая-то функция активации. Маша хочет научиться делать для такой нейронной сетки градиентный спуск.

а) Запишите Машину нейросеть, как сложную функцию.
Решение
Чтобы записать нейросеть как сложную функцию, нужно просто последовательно применить все слои
б) Предположим, что Маша решает задачу регрессии. Она прогоняет через нейросетку одно наблюдение. Она вычисляет знчение функции потерь \(L(w_1, w_2, w_3) = \frac{1}{2} \cdot (y - \hat y)^2\). Найдите производные функции \(L\) по всем весам \(w_k\).
Решение
Запишем функцию потерь и аккуратно найдём все производные
Делаем это по правилу взятия производной сложной функции
в) В производных повторяются одни и те же части. Постоянно искать их не очень оптимально. Выделите эти части в прямоугольнички.
Решение
Выделим в прямоугольники части, которые каждый раз считаются заново, хотя могли бы переиспользоваться.
Если бы слоёв было бы больше, переиспользования возникали бы намного чаще. Градиентный спуск при таком подходе мы могли бы сделать точно также, как и в любых других моделях
Проблема в том, что такой подход из-за постоянных перевычислений будет работать долго, за \(O(m^2)\), где \(m\) – глубина нейронной сетки. Алгоритм обратного распространения ошибки помогает более аккуратно считать производную и ускорить обучение нейросетей.
г) Выпишите все производные в том виде, в котором их было бы удобно использовать для алгоритма обратного распространения ошибки, а затем, сформулируйте сам алгоритм. Нарисуйте под него удобную схемку.
Решение
Выпишем алгоритм обратного распространения ошибки. Договоримся до следующих обозначений. Буквами \(h^k\) будем обозначать выход \(k-\)го слоя до применения функции активации. Буквами \(o^k\) будем обозначать выход после применения функции активации. Например, для первого слоя:
Сначала мы делаем прямой проход по нейросети (forward pass):

Наша нейросеть — граф вычислений. Давайте запишем для каждого ребра в рамках этого графа производную.
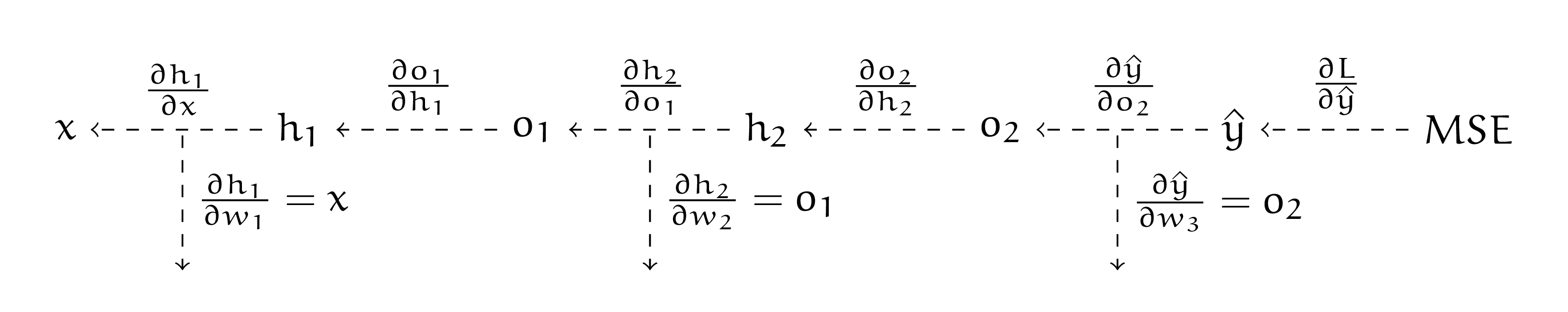
Мы везде работаем со скалярами. Все производные довольно просто найти по графу, на котором мы делаем прямой проход. Например,
Если в качестве функции активации мы используем сигмоиду
тогда
Получается, что
Осталось только аккуратно записать алгоритм. В ходе прямого прохода мы запоминаем все промежуточные результаты. Они нам пригодятся для поиска производных при обратном проходе. Например, выше, в сигмоиде, при поиске производной, используется результат прямого прохода \(o_2.\)
Заведём для накопленного значения производной переменную \(d\). На первом шаге нам надо найти \(\frac{\partial L}{\partial w_3}\). Сделаем это в два хода
Для поиска производной \(\frac{\partial L}{\partial w_2}\) переиспользуем значение, которое накопилось в \(d\). Нам надо найти
Часть, выделенную в прямоугольник мы будем переиспользовать для поиска \(\frac{\partial L}{\partial w_1}\). Хорошо бы дописать её в \(d\) для этого. Получается, вторую производную тоже надо найти в два хода
Осталась заключительная производная \(\frac{\partial L}{\partial w_1}\). Нам надо найти
Снова делаем это в два шага
Если бы нейросетка была бы глубже, мы смогли бы переиспользовать \(d\) на следующих слоях. Каждую производную мы нашли ровно один раз. Это и есть алгоритм обратного распространения ошибки. Одна его итерация отрабатывает за \(O(m),\) где \(m\) – глубина нейронной сетки. В случае матриц происходит всё ровно то же самое, но дополнительно надо проследить за всеми размерностями и более аккуратно перемножить матрицы.