2. Туда и обратно#
Маша хочет сделать шаг обратного распространения ошибки через рекуррентную ячейку для последовательности \(y_0 = 0, y_1=1, y_2 = -1, y_3 =2\). Скрытое состояние инициализировано как \(h_0 = 0\). Все веса инициализированы как \(0.5\). Во всех уравнениях, описывающих ячейку нет констант. В качестве функций активаций Маша использует \(ReLU\). В качестве функции потерь Маша использует \(MSE\).

а) Сделайте прямой шаг через ячейку. Для каждого элемента последовательности постройте прогноз. Посчитайте значение ошибки.
Решение
Рекуррентную сеть можно рассматривать, как несколько копий одной и той же сети, каждая из которых передает информацию последующей копии. Веса для всех копий одинаковые.
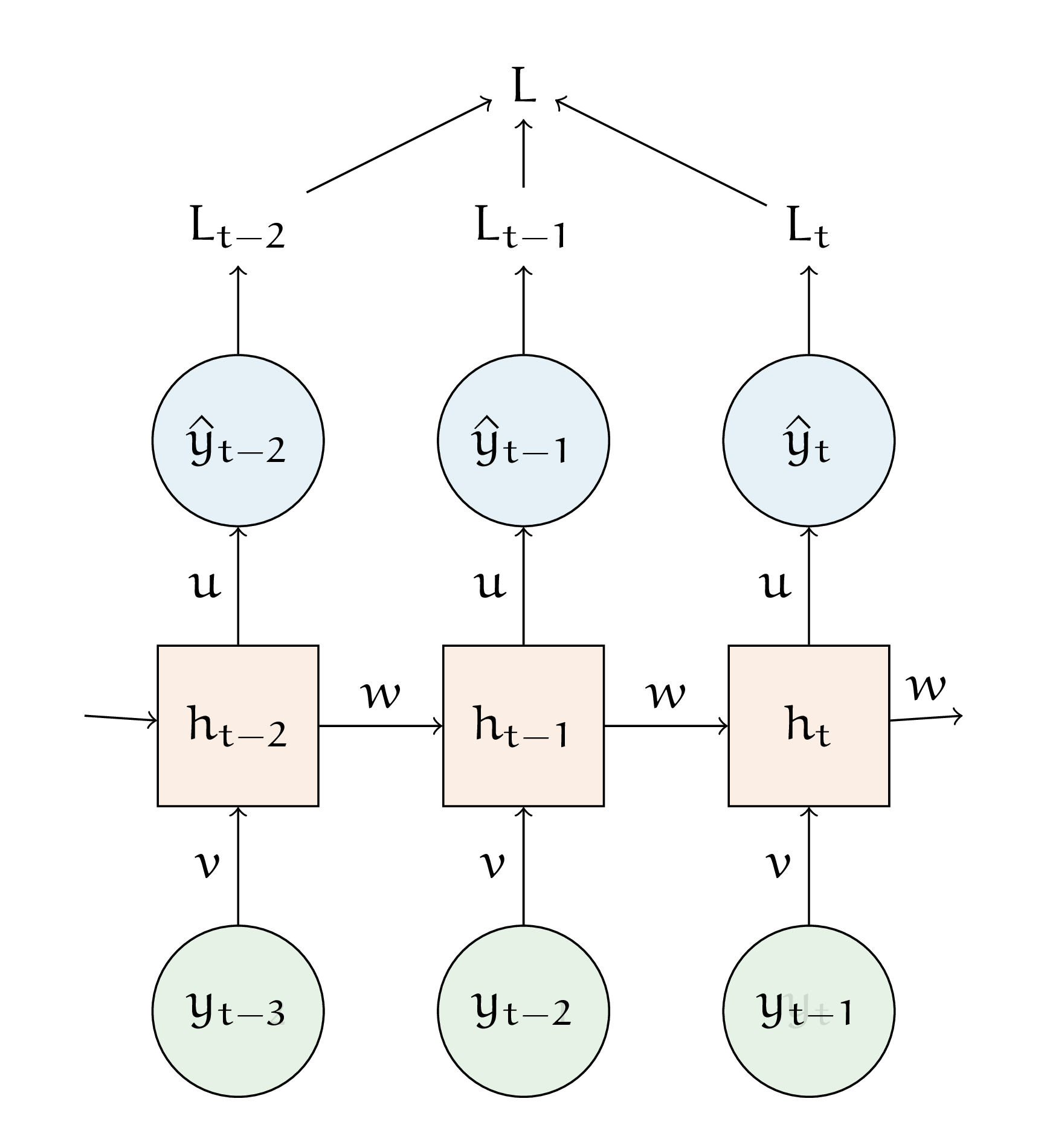
Когда мы строим прогнозы, мы движемся слева направо и сверху вниз. Чтобы сделать прямой шаг, нам нужно подставить соотвествуюшие значения в формулы пересчёта
Тогда мы получим
\(t\) |
\(0\) |
\(1\) |
\(2\) |
\(3\) |
|---|---|---|---|---|
\(h_t\) |
\(0\) |
\(0\) |
\(0.5\) |
\(0.375\) |
\(\hat y_t\) |
- |
\(0\) |
\(0.25\) |
\(0.1875\) |
\(y_t\) |
\(0\) |
\(1\) |
\(-1\) |
\(2\) |
\(L_t\) |
- |
\(1\) |
\(1.5625\) |
\(3.285\) |
Получаем итоговое значение ошибки нашего нейрона на всей последовательности
Именно его нам надо будет уменьшать в ходе обратного распространения ошибки.
б) Выпишите для рекуррентного нейрона производные функции ошибки по весам \(u,v,w\).
Решение
Выведем формулы для шага по весам \(u\). Нам нужно найти производную \(\frac{\partial L}{\partial u}\). Итоговая ошибка ищется как сумма ошибок на каждом элементе последовательности.
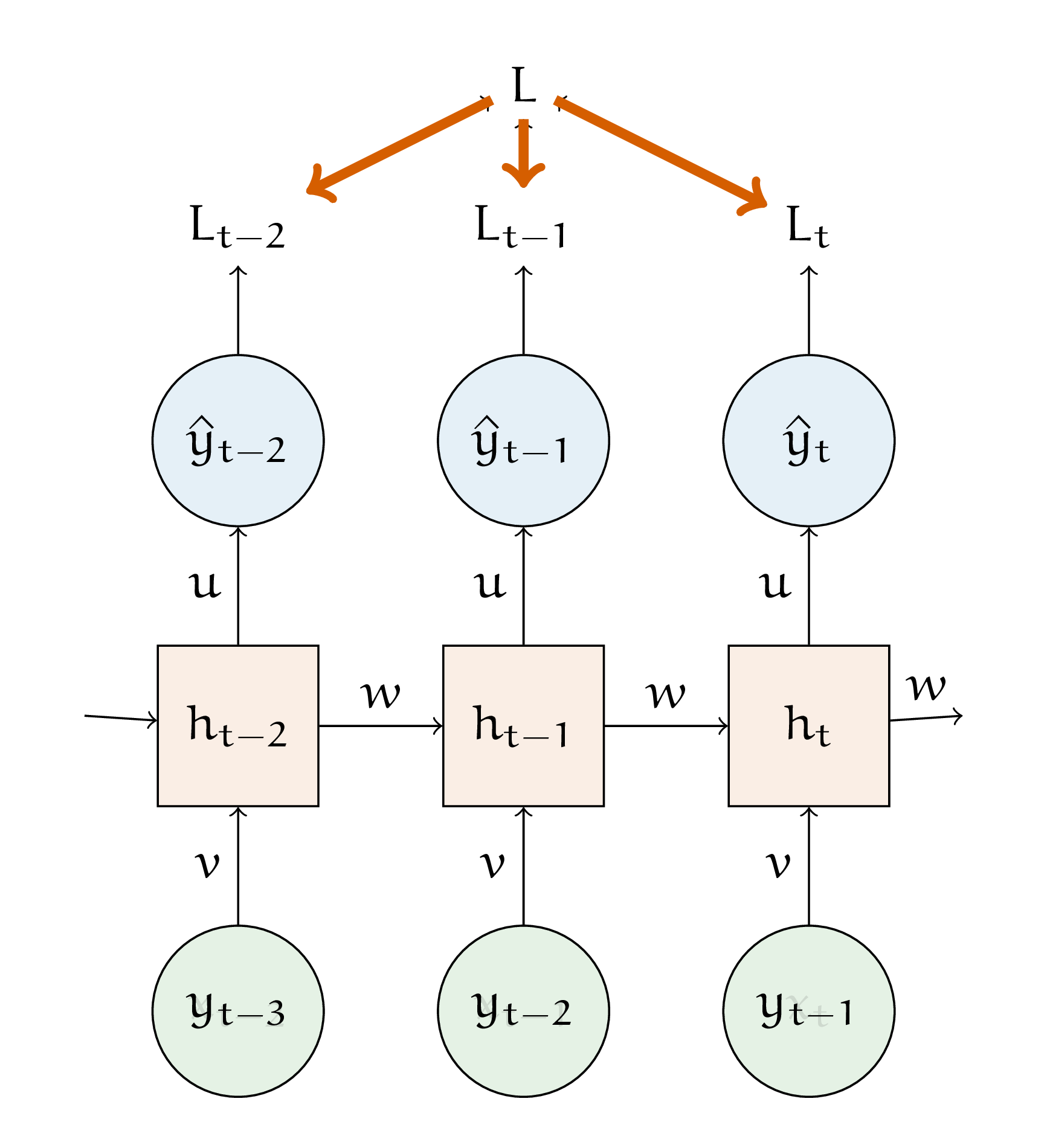
Это означает, что наша производная разваливается в сумму производных
Посмотрим на одно слагаемое.

Для него производную можно расписать через предыдущие элементы нашего графа вычислений
Все эти производные можно найти, если вспомнить формулы рекуррентного нейрона
Параметр \(u\) присутствует в уравнении только в формуле для \(y\). Внутри \(h_t\) этот вес нигде не встречается, из-за этого производная оказывается простой
Теперь найдём производную по весу \(w\).
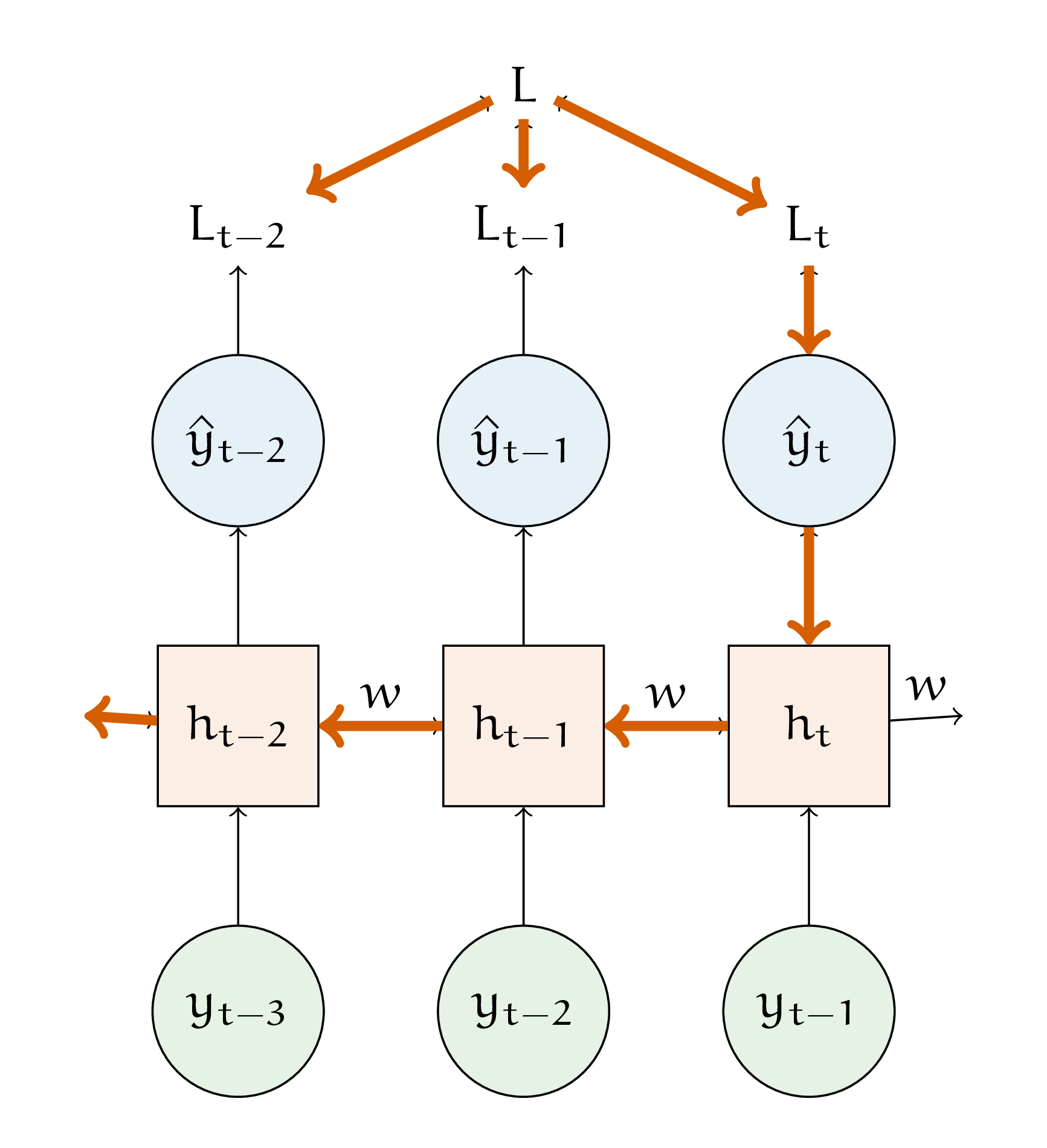
С этим весом возникнут проблемы, так как он участвует в каждом пересчёте \(h_t\). Придется брать производную назад во времени (backpropagation through time)
В формулах пересчёта вес \(w\) стоит перед \(h_{t-1},\) которая тоже зависит от \(w\)
Значит надо найти \(\frac{\partial h_{t-1}}{\partial w},\) которая будет зависеть от \(h_{t-2}\), которая тоже зависит от \(w\) и так далее
Итоговая производная имеет вид
Осталась заключительная производная по весу \(v\)
В ходе взятия этой производной мы нигде не упираемся в \(h_{t-1},\) поэтому назад во времени идти не нужно. Давайте подставим соотвествующие части уравнений и получим ответ
в) Сделайте шаг обратного распространения ошибки по весу \(u\)
Решение
Итак
где
Получается, что
В итоге
По весам \(w\) и \(v\) также можно сделать шаг обратного распространения ошибки, но расчёты будут более неприятными.
г) Как изменится нейрон, если на вход в него будет идти не одна последовательность, а несколько?
Решение
В таком случае все веса превратятся в матрицы. Формулы останутся теми же самыми.